
1. 集合框架
Java 集合,也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 、Queue。
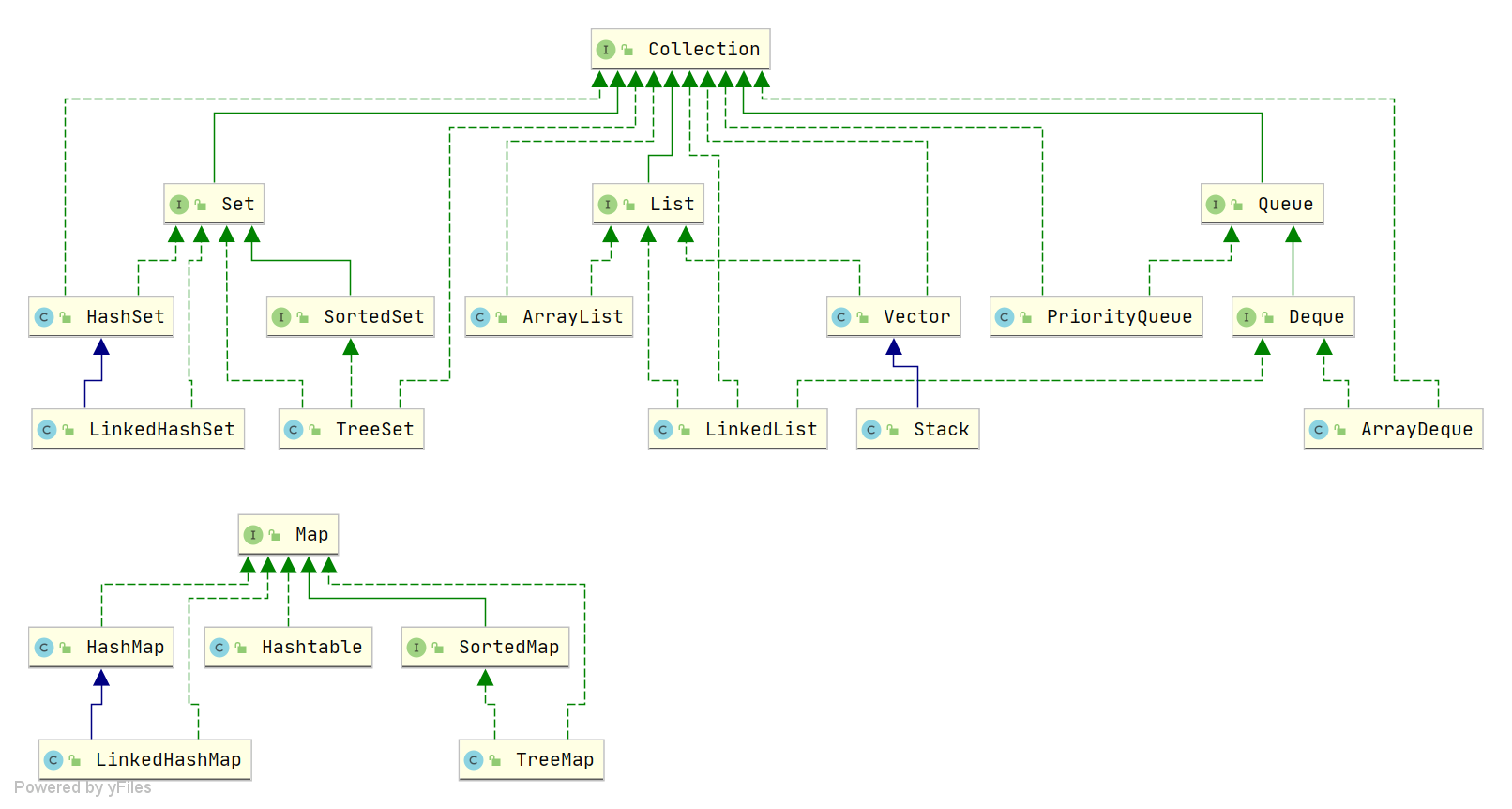
总结:
List:
ArrayList:Object[] 数组。
Vector:Object[] 数组。
LinkedList:双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)。
Set:
HashSet(无序,唯一): 基于 HashMap 实现的,底层采用 HashMap 来保存元素。
LinkedHashSet: LinkedHashSet 是 HashSet 的子类,并且其内部是通过 LinkedHashMap 来实现的。
TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)。
Queue:
PriorityQueue: Object[] 数组来实现小顶堆。
DelayQueue:PriorityQueue。
ArrayDeque: 可扩容动态双向数组。
Map:
HashMap:JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
Hashtable:数组+链表组成的,数组是 Hashtable 的主体,链表则是主要为了解决哈希冲突而存在的。
TreeMap:红黑树(自平衡的排序二叉树)。
2. List
ArrayList
底层为动态扩容数组,查询快,增删慢,允许null,可重复,自动扩容1.5倍,线程不安全。
内部主要依赖两个字段:
transient Object[] elementData; // 存储数据的数组
private int size; // 当前元素数量初始化(数组长度为0,不分配容量,第一次add时分配初始容量10):
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; // 空数组
}添加元素:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保容量够
elementData[size++] = e;
return true;
}若ensureCapacity判断容量不足,则进入扩容(grow)机制,新容量为原容量的1.5倍,如果新容量仍不足,则直接扩充到指定最小容量:
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}查询元素由于底层是数组,有索引,可以O(1)访问,而删除元素需要将后续元素前移,删除越靠前的元素越慢。
ArrayList不是线程安全的,多线程中可能出现数据丢失和并发修改异常。
可使用Collections.synchronizedList();:
List list = Collections.synchronizedList(new ArrayList<>());或使用CopyOnWriteArrayList(适用读多写少场景)
LinkedList
基于双向链表实现,查询慢,首尾增删快O(1),线程不安全
核心字段:
transient int size = 0;
transient Node<E> first;
transient Node<E> last;每个节点为一个内部类Node:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E item, Node<E> next) {
this.item = item;
this.next = next;
this.prev = prev;
}
}其同时实现了List(顺序存储结构—双向链表)、Deque(双端队列)、Queue(普通队列),所以可以作为顺序集合、栈(Stack)、队列(Queue)、双端队列(Deque)来使用。
首位添加/删除元素都是O(1),由于链表结构必须从头尾遍历,查询元素为O(n),中间添加/删除由于需要先查询,所以也是O(n)。所以LinkedList不适于频繁访问。
LinkedList是线程不安全的,可使用Collections.synchronizedList();:
List list = Collections.synchronizedList(new LinkedList<>());但大多数场景推荐使用并发队列类替代,如ConcurrentLinkedQueue、ArrayBlockingQueue、LinkedBlockingQueue、ConcurrentLinkedDeque
Vector(过时)
Vector 是 Java 1.0 就存在的早期动态数组类,是 ArrayList 的前身。
它与 ArrayList 非常相似,主要区别是:Vector 是线程安全的(方法全部使用 synchronized 关键字)。
因为是早期类,后续被看作“遗留类”(Legacy Class),现在通常不推荐使用。
Vector扩容机制默认为2倍,但可以指定固定大小
为什么 Vector 已经不推荐使用?
同步开销大、加锁方式粗糙
转向更现代、更细粒度锁的并发集合类:CopyOnWriteArrayList、Collections.synchronizedList(new ArrayList<>())
扩容策略 2 倍容易浪费内存
API 风格老旧(enumeration、addElement)
Stack(过时)
Stack是一个栈数据结构实现类,用于实现后进先出。由于继承于Vector,出入栈操作都基于Vector的加锁方法,Stack是线程安全的,下标访问于扩容机制与Vector一致。
底层由动态数组实现:
protected Object[] elementData;
protected int elementCount;提供了栈操作核心方法:
E push(E item) // 入栈
E pop() // 出栈
E peek() // 查看栈顶元素但不移除
boolean empty() // 是否为空
int search(Object o) // 搜索元素在栈中的位置(从 1 开始计数)但Stack也不推荐使用,因为他太简单,性能太差,继承Vector的设计也不好使得Stack暴露了一些不该被Stack使用的方法,官方推荐使用ArrayDeque替代Stack。
3. Set
HashSet
HashSet是基于哈希表(HashMap)实现的无序不重复的集合,允许null值,查询插入删除的性能都接近O(1),非线程安全。
关键字段:
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();添加元素,调用HashMap的put方法:
map.put(e, PRESENT);而HashMap的put方法:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //hash(key)计算哈希值
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
//如果是第一次调用table还没有初始化
n = (tab = resize()).length; //初始化默认容量16
if ((p = tab[i = (n - 1) & hash]) == null)
//(n - 1) & hash相当于hash % n,p = tab[i]取出桶位置的第一个节点,判断是否为空
tab[i] = newNode(hash, key, value, null); //为空插入一个Node
else {
//不为空发生哈希冲突
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//判断第一个节点是否为目标Key
e = p; //是,说明要插入的 key 已经存在,e 指向它
else if (p instanceof TreeNode) //判断是否为红黑树节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //是则进入红黑树插入逻辑
else { //以上都不是即为链表
for (int binCount = 0; ; ++binCount) { //遍历链表在链尾插入新节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) //如果链表长度大于等于8
treeifyBin(tab, hash);
//转为红黑树(但在treeifyBin方法会先检查table.length是否 ≥ 64,否则优先扩容)
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) //若key已存在
break; //不插入,而是后面覆盖 value
p = e;
}
}
if (e != null) { // 若找到重复key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; // 覆盖 value
afterNodeAccess(e);
return oldValue; //返回 oldValue
}
}
++modCount; //触发 fail-fast,迭代器检测 modCount 是否变化用于 fail-fast
if (++size > threshold) //检查是否超过阈值 threshold,触发扩容,threshold = capacity × loadFactor,默认threshold = 12,capacity = 16,loadFactor = 0.75
resize(); //扩容为两倍
afterNodeInsertion(evict);
return null; //返回 null,表示是新插入 key
}判断重复元素必须满足hashCode() 值相等且equals() 返回 true,所以若要对象存入 HashSet,一定要重写 equals 和 hashCode 保证一致性。
扩容机制,同样来自HashMap:初始容量默认 16,负载因子 loadFactor = 0.75,当 size > capacity × loadFactor 触发扩容,扩容后容量变为原来的 2 倍。扩容不仅需要创建一个更大的数组,还需要重新计算所有元素的位置,非常耗时,建议在创建时指定预估容量:
new HashSet<>(expectedSize);由于HashSet中元素位置由hash值决定,与添加顺序无关,所以HashSet是无序的。
HashSet不是线程安全,可以使用同步包装:
Set s = Collections.synchronizedSet(new HashSet<>());或使用线程安全方案:ConcurrentHashMap.newKeySet()、CopyOnWriteArraySet
LinkedHashSet
LinkedHashSet 是 HashSet 的子类,本质上是:“带有插入顺序(或访问顺序) 的 HashSet,性能基本与 HashSet 相同
HashSet 的底层是 HashMap,LinkedHashSet 的底层是LinkedHashMap
LinkedHashMap 在 HashMap 的基础上增加了一个双向链表:
Node<K,V> before; // 前驱节点
Node<K,V> after; // 后继节点这样所有节点都按插入顺序链接成了一个双向链表,迭代是按照链表顺序遍历,而且迭代链表不需要跳空桶,性能反而可能比 HashSet 快。
添加元素的实际逻辑为:
HashSet.add() → 调用 HashMap.put()
HashMap.put() → 实际调用的是 LinkedHashMap.put()
LinkedHashMap.put() 将元素加入数组 + 加入双向链表
LinkedHashMap还提供了另一种访问顺序(access-order = true):LRU缓存,被访问的元素会被移动到链表尾部。LinkedHashSet 本身没有公开 accessOrder,但通过 LinkedHashMap 构造器也能实现访问顺序维护。
LinkedHashSet的扩容机制与HashSet完全一致,扩容过程只影响数组,不会改变链表中的前后关系,链表顺序保持不变。
LinkedHashSet也是非线程安全的,可同步包装:
Set s = Collections.synchronizedSet(new LinkedHashSet<>());可使用线程安全替代方案:ConcurrentLinkedQueue(队列)、LinkedBlockingDeque
TreeSet
TreeSet是Java中一个有序、不重复的集合,可以自动排序,不可存储null,增删查时间复杂度为O(logN),基于红黑树实现,底层结构为TreeMap。
关键字段:
private transient NavigableMap<E,Object> m;
public TreeSet() {
this(new TreeMap<E,Object>());
}TreeSet 中所有元素被作为 TreeMap 的 key 保存:
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}TreeMap.put 的核心逻辑为:根据 comparer 或 compareTo 递归定位节点,如果 compare == 0 → 重复,不插入,否则插入新节点。调整红黑树(旋转 + 变色),保持平衡。
所以TreeSet 的排序实际为TreeMap 的排序,TreeSet 的存储结构实际为TreeMap 的红黑树。
红黑树是一种平衡二叉排序树,特点:
每个节点有颜色(红或黑)
根节点必须为黑
不能连续两个红色节点
任一节点到叶子节点的所有路径上黑色节点数相同
每次插入或删除后会自动旋转与变色确保平衡
所有操作 O(log N)
TreeSet 的“重复判断”是基于排序比较,必须能比较元素,有两种比较方式:
自然排序:比如 Integer、String 默认实现了 Comparable,e1.compareTo(e2) 比较
自定义排序:传入Comparator覆盖原有排序
TreeSet<Person> set = new TreeSet<>(
(a, b) -> a.age - b.age
);4. Queue
Queue是Conllection的子接口,其下有两个重要子接口-Deque(双端队列)和BlockingQueue(阻塞队列)
常用实现类除了LinkedList,还有PriorityQueue(优先级队列)
Deque的常见实现类有ArrayDeque
BlockingQueue常用于线程通信,常见实现类如下:
PriorityQueue
优先级队列,出队顺序并非按插入顺序而是按优先级决定,无序(按照堆结构在数组中存储),底层结构为二叉堆,不能保证先进先出,也不能保证全局排序,迭代器数据无意义。
底层结构:动态扩容的数组Object[]+堆结构维护优先级顺序,满足堆性质——任意节点都不比它的父节点更小
出入队O(logn),查看最小元素O(1),删除元素最坏为O(n),每次增删元素需要上浮/下沉以保证堆结构。
扩容机制:底层数组默认容量为11,1.5倍扩容
典型使用场景有找最大k个数、合并k个有序链表、任务调度等等。
ArrayDeque
ArrayDeque是Java1.6引入的一个基于循环数组的双端队列实现,是实现栈和队列的首选,不支持存储null值,非线程安全。
底层结构:
transient Object[] elements; // 循环数组
transient int head; // 指向队头元素
transient int tail; // 指向队尾之后的位置(空位)head 位置存储 队头元素,tail 位置是 可插入队尾的空槽,数组下标是循环使用的(mod 数组长度),head/tail 指针不断移动,当到达数组末端时会“绕回”数组开头(数组长度总是 2 的幂,使用位运算代替取模操作):
位置 = (位置 + 1) & (数组长度 - 1)增删两端元素O(1),内存占用少,连续存储。
扩容机制:当队列满时,创建一个新数组,容量 *= 2,将旧数组从 head 开始 连续复制 到新数组起始位置,head 被重置为 0,tail = 原大小。
BlockingQueue接口相关
继承于Queue的一个接口,支持当队列没有元素时一直阻塞,直到有元素,以及如果队列已满,一直等到队列可以放入新元素时再放入。常用于生产者-消费者模型中,生产者线程会向队列中添加数据,而消费者线程会从队列中取出数据进行处理。
常见实现类:
ArrayBlockingQueue(数组 + 有界):创建时指定固定大小,数组结构有界队列,锁竞争强,适用于固定容量的生产者-消费者模型。
LinkedBlockingQueue(链表 + 无界):链表结构,并发能力比 ArrayBlockingQueue 好(生产与消费的锁分离),适用于大量任务排队和线程池(ThreadPoolExecutor 的 workQueue 默认使用它)
PriorityBlockingQueue:是带优先级的无界阻塞队列,常用于任务调度和定时任务。元素必须实现Comparable接口或者在构造函数中传入Comparator对象,并且不能插入 null 元素。
DelayQueue(延时队列):其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
SynchronousQueue(无容量队列):同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,SynchronousQueue通常用于线程之间的直接传递数据,线程池 CachedThreadPool 使用它。
LinkedBlockingDeque(双端阻塞队列):可从头/尾阻塞插入、阻塞获取元素,用于复杂生产者消费者模型。
5. Map
HashMap
HashMap是Java中最广泛的键值对结构,key不重复,支持null值,插入删除查询都接近O(1),基于数组+链表+红黑树实现(Java8前只有数组+链表),非线程安全。
底层由三种数据结构实现:
数组Node<K,V>[] table为核心数据结构,长度为2的幂,每个数组位置称为桶。
链表用于解决哈希冲突,当多个key落到同一个桶中时,用链表使用尾插法链起来。
红黑树用于解决链表过长的问题,当链表长度>=8且数组长度大于等于64时,将链表树化,树化后查询性能从O(n)变为O(logn),性能提升。
哈希扰动优化:指HashMap中对key的哈希值计算方式做了扰动优化,可以避免碰撞集中在某些桶,提高哈希分布均匀度,代码为:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}HashMap添加元素的流程在上文HashSet中讲过,可以回看。
HashMap的数组长度为2的幂,n-1机制为全1,使用位运算效率高且可以使哈希分布均匀。
HashMap不是线程安全的,多线程并发put可能导致数据丢失、hash链表断裂和死循环(Java8修复了死循环问题,但仍然非线程安全),可以使用线程安全替代方案:ConcurrentHashMap、Collections.synchronizedMap()
LinkedHashMap
HashMap的子类,在 HashMap 的基础上增加了一个双向链表,有序且性能仍然接近O(1),适合LRU缓存(支持accessOrder)
LinkedHashMap 的每一个节点都是 HashMap.Node 的增强版:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after; // 双向链表指针
}多了两个指针,形成双向链表用于维护全局顺序。
可以支持两种方式保持顺序(LinkedHashSet中提到过):
key的插入顺序
访问顺序:只要访问 key(get 或 put 已存在 key),就会把节点移动到链表末尾,是实现LRU的核心。
扩容与HashMap一致。
在LinkedHashMap中,链表维护只是简单的引用指针操作,节点创建时就顺带链接,按照访问顺序移动节点到尾部也只是简单的三次指针操作,时间复杂度不受影响,性能仍然与HashMap差不多。
HashTable(过时)
HashTable是Java1.0就存在的哈希表实现,所有方法都加synchronized,线程安全,不允许null key和null value。底层使用数组+链表,性能较差,已经不推荐使用。
Hashtable 的底层与 HashMap 类似:
使用数组存储桶(Entry<K,V>[])
每个桶是一个链表(单链表)
扩容机制:初始容量为11,新容量 = 旧容量 × 2 + 1,重新 rehash 所有键值对,扩容性能差。
且其迭代器为Enumeration,不是fail-fast,不会抛 ConcurrentModificationException。
TreeMap
是基于红黑树实现的有序Map集合,不允许null key,查找插入删除O(log n),key必须可比较,非线程安全。
TreeMap的底层结构为红黑树(RBT),Node结构为典型红黑树节点结构:
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color; // 红或黑
}红黑树五大特性:
节点是红或黑
根节点是黑
红节点不能连在一起(红节点不能有红子节点)
任意节点到叶子的路径上黑节点数相同
为保持树高度接近 log n,插入/删除时会通过旋转修复平衡
这就能解释为什么TreeMap性能快:红黑树高度始终 O(log n),不会退化为链表
排序方法有两种,TreeMap中比较key是否相等使用的也是compareTo方法:
自然排序,使用key.compareTo()方法排序
自定义比较器Comparator,构造器传入
put添加元素逻辑(O(log n)):
从根节点开始,根据 compare(key1, key2) 找插入位置
插入节点当作红节点(红黑树性质)
执行红黑树旋转与染色,修复平衡
完成插入
TreeMap还提供了特有的强大API:
范围查找(获取 key < x 的所有元素-headMap、获取 key ≥ x 的所有元素-tailMap、获取 (a ≤ key < b) 范围-subMap、导航功能-ceiling / floor / higher / lower)
总的来说:HashMap 快,但无序;TreeMap 较慢,但有序和可导航。
6. fail-fast机制
fail-fast是是大多数 java.util 非线程安全集合的 Iterator 自愿采用的策略,是一种 “快速失败的检测机制”,它用于检测迭代过程中,集合结构是否被外部修改(非迭代器自身)。如果是则抛 ConcurrentModificationException。
实现原理(modCount自增 + expectedModCount 检查):
所有支持 fail-fast 的集合类中,都有一个字段:
protected transient int modCount = 0;每次结构性修改(add/remove/clear/rehash)都会:modCount++
迭代器创建时,会记录当前 modCount 值:
int expectedModCount = modCount;每次迭代(next/remove)都会检查:
if (modCount != expectedModCount)
throw new ConcurrentModificationException();该机制的意义在于尽早发现错误状态(并发修改)并快速失败,让程序员察觉问题,否则迭代结果可能错误、不一致,但程序仍继续执行,更危险。
7. 线程安全集合
Java提供的线程安全集合有三类
一类就是早期使用synchronized修饰所有方法的同步集合:Vector、Stack、HashTable
第二类是Java提供的同步包装集合Collections.synchronizedXXX,实现方法也是在方法上加锁,性能差,但比过时的集合API更现代,相较来说更推荐使用。如:
Collections.synchronizedList(list)
Collections.synchronizedMap(map)
Collections.synchronizedSet(set)第三类就是并发包集合(java.util.concurrent),是现代Java推荐使用的真正线程安全的高性能集合,包括:
这些集合是如何保证线程安全的?
写时复制方案Copy-On-Write:
原理为读不加锁,写操作时复制整个数组,修改新数组,写完后替换引用。
优点是读不加锁性能高
缺点是写操作开销大,占用内存大
代表类为:CopyOnWriteArrayList、CopyOnWriteArraySet
无锁算法CAS(Compare-And-Swap):
原理为当期望值与当前值相等时才关系,若不相等则重试
优点为读操作完全无锁,写操作竞争少,吞吐量高,是现代并发的重要基础
代表类为:ConcurrentHashMap(JDK8版本)、ConcurrentLinkedQueue、ConcurrentLinkedDeque
分段锁 / Node 锁:
是ConcurrentHashMap(JDK7的方案)
原理为读操作无锁(volatile + 内存可见性),写操作只锁住单个桶的链表头或树节点
允许多个线程同时写不同桶,高并发性能强
阻塞队列(BlockingQueue):
原理为put() 队列满时阻塞,take() 队列空时阻塞,属于生产者-消费者模型
实现类有:LinkedBlockingQueue、ArrayBlockingQueue、SynchronousQueue等