
1. 基本数据类型
Java有8种基本数据类型:
数字类:
整数型:byte、short、int、long
浮点型:float、double
字符型:char
布尔型:boolean
boolean 的大小在 JVM 规范中并未严格规定为 1 bit,大多数实现中会使用 1 byte 或更多字节。
2. 基本类型和包装类型
包装类型可以为null,而基本类型不可以。
包装类型可以用于POJO中,而基本类型不可以(数据库的查询结果可能是null,如果使用基本类型的话,因为要自动拆箱,就会抛出 NullPointerException的异常)。
包装类可以用于泛型,而基本类型不可以。
基本数据类型的局部变量存储于Java虚拟机栈的局部变量表中,成员变量存储于Java虚拟机的堆中。而包装类型全部存放于堆中。
包装类型的值相同,但不一定不相等,需使用equals()方法判断。
自动拆箱、自动装箱(JavaSE5后):用户可直接对基本类型和包装类型进行相互赋值,而系统通过 valueOf() 与 xxxValue()等方法完成转换。
包装类型的缓存机制:Byte、Short、Integer、Long这 4 种包装类默认创建了数值 [-128,127] 的相应类型的缓存数据,Character创建了数值在 [0,127] 范围的缓存数据,Boolean 直接返回True or False。如果在范围内,则复用已有对象,超出范围则创建新对象。
3. 面向对象与面向过程
面向过程倾向于将问题拆解为一个个方法步骤,通过方法执行实现功能。
面向对象先抽象出对象,用对象执行方法的方式解决问题。
面向过程一般比较简单直接,面向对象虽然复杂,但是易于维护、拓展和复用。
面向对象的三大特征:封装、继承、多态
封装:把一个对象的状态信息(属性)隐藏在对象的内部,外界不能直接访问,但可以通过提供的方法来操作。
继承:可以在已存在的类的基础上创建新类,子类拥有父类的全部属性和方法,子类可以拥有自己的方法,子类可以通过自己的方式实现父类的方法。
多态:同一个方法在不同对象上表现出不同的行为,通过继承和方法重写实现。父类的引用可以指向子类的对象,并调用子类重写的方法。三个必要条件为:继承、重写、父类引用指向子类对象。
4. 接口和抽象类
接口用来约束类的行为,抽象类强调所属关系和代码复用。
共同点:都不可直接实例化,需要先被实现或继承才能创建对象。都可以包含抽象方法,即无方法体,在子类或实现类中定义。
不同点:
Java不支持多继承,一个类只能继承一个类。但一个类可以实现多个接口,一个接口也可以继承多个其他接口。
接口中的成员变量只能是public static final类型的,不能被修改且必须有初始值。抽象类的成员变量可以有任何修饰符(private, protected, public),可以在子类中被重新定义或赋值。
Java 8 之前,接口中的方法默认是 public abstract ,也就是只能有方法声明。自 Java 8 起,可以在接口中定义 default(默认) 方法和 static (静态)方法。 自 Java 9 起,接口可以包含 private 方法。抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须在子类中实现。非抽象方法有具体实现,可以直接在抽象类中使用或在子类中重写。
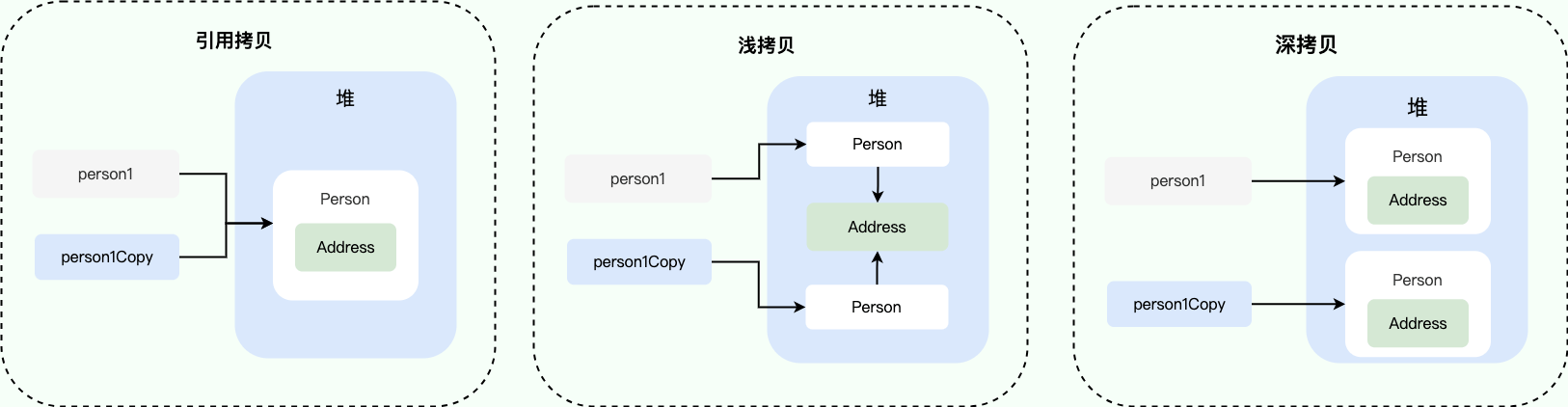
5. 浅拷贝、深拷贝、引用拷贝
这三个概念的核心区别在于:在内存中复制了多少层级的数据,以及新旧对象之间是否还存在关联。
引用拷贝:仅仅复制了对象的内存地址(引用),没有创建任何新对象,两个变量指向堆内存中的同一个对象。这时修改任意一个变量也会影响另一个变量。
浅拷贝:创建一个新对象,然后将原对象中的成员变量复制到新对象中。如果成员是基本类型则拷贝其值。如果成员是引用类型则拷贝其内存地址。新旧对象在内存中是独立的“容器”,但容器里装的“引用类型数据”还是共享的。修改第一层数据(如基本类型),不会影响原对象。但修改内部引用的对象数据,会影响原对象。
深拷贝:创建一个新对象,并递归地将原对象中的所有成员(包括引用的对象、引用对象的引用对象……)全部复制一份。新旧对象在内存中完全独立,互不干涉。
6. ==与equals()
==用于比对两个变量是否指向同一个对象(同一个内存地址)。对于基本数据类型比较的是值,对于引用类型比较的是引用地址是否相同。
equals()方法是Object的方法,默认实现比较的也是引用是否相同,但可被子类重写,常见类都进行了重写来比较内容。自定义类要比较内容必须重写equals()方法和hashCode()方法。
==判断需注意:
包装类型缓存机制(前面提到了)、
常量折叠优化(在编译期提前计算出所有由常量组成的表达式,直接把结果写入字节码中,而不是在运行时再计算)、
字符串还需额外注意常量池(字面量字符串会自动放入常量池,字符串常量拼接会触发常量折叠,结果也进入常量池。字符串字面量创建对象时若常量池中已有则会直接赋给当前引用)。
hashCode()是什么?为什么要重写hashCode()方法?
hashCode()是Object的方法,即所有类的方法,该方法可以获取哈希码(确定对象在哈希表中的索引位置),主要为哈希表如HashMap、HashSet等提供高效存取的支持。
Java规定如果两个对象通过equals方法判断为相等,那么他们的hashCode()方法必须返回相同的值。但反之不一定(因为可能出现哈希冲突的情况)重写equals()方法时必须重写hashCode()方法保证相同的对象拥有相同的哈希码从而确保哈希表功能正常。
重写时需注意保证参与equals()方法判断的字段都要参与hashCode()方法的计算,否则容易出现逻辑矛盾。
7. String、StringBuilder、StringBuffer
String是不可变的,使用final和private修饰,一旦创建内容不可修改,任何对String对象的修改都会产生一个新的String对象。这样设计的原因一是线程安全,多线程时不需要加锁不会有读写冲突;二是可以防止恶意或者意外修改;三是为了常量池优化的的可行性,只有不可变才能使常量池中的数据安全的复用;四是由于String常作为HashMap的Key,保证Key的hash不变就可以只缓存一次而不必重复计算。
Java为字符串维护一块特殊的内存叫做常量池,使用字面量创建的字符串会放入常量池中,复用常量池的对象,而使用new String()创建的字符串会在堆内存创建一个对象(但该对象仍使用常量池中对象赋值,常量池中没有则创建后赋值)。
String在Java8前,使用的是char[]存储,char占两个字节,但大部分字符用ASCII表示只需一个字节,于是在Java9引入了紧凑字符串,使用byte[]+coder(表示编码方式)存储字符串,大大减小了内存占用。
String是不可变的,在String c = a + b;中其实使用的是可变的StringBuilder,此处为语法糖,编译器会转换为String c = new StringBuilder().append(a).append(b).toString(); 另外一个可变的是StringBuffer,两者都继承于AbstractStringBuilder,没有使用final和private修饰,且提供了一些字符串基本操作方法,两者区别在于StringBuilder线程不安全而StringBuffer线程安全(加了同步锁)。
直接使用+虽然与使用StringBuilder是一样的,但是由于使用+每次会创建新的StringBuilder而不会复用已有对象,所以性能不如StringBuilder(Java9后对简单字符串拼接做了内存优化)
8. 异常
Java的异常体系如下:
Throwable(所有异常根类)
├── Error(程序无法处理,JVM级别的问题)
│ ├── OutOfMemoryError
│ ├── StackOverflowError
│ ├── ThreadDeath
│ └── ...
└── Exception(异常,可以/需要处理)
├── RuntimeException(非受检异常)
│ ├── NullPointerException
│ ├── IndexOutOfBoundsException
│ ├── ArithmeticException
│ ├── IllegalArgumentException
│ └── ...(常见运行时错误)
└── Checked Exception(受检异常)
├── IOException
├── SQLException
├── ClassNotFoundException
├── FileNotFoundException
└── ...(必须处理)Throwable为所有异常的根类,其有两个子类Error与Exception:
Error异常为严重错误,不需要也不建议捕获,是系统/JVM的问题,程序通常无法继续执行
Exception是程序可以处理的异常,可以用catch捕获,其中可以分为Checked Exception和RuntimeException:
Checked Exception为受检异常,是编译器强制要求处理的异常,程序必须捕获处理,一般表示业务层处理的问题
RuntimeException(及其子类)为运行时异常,由JVM在运行时抛出,通常可以通过修改代码解决
9. 泛型
泛型是JDK5引入的新特性,允许把类型当作参数传递,编译器检测传入的类型,比如List<String> list = new ArrayList<>();。
泛型的三种定义方式如下:
//泛型类
public class Box<T> {
private T value;
}
//泛型接口
public interface Generator<T> {
T next();
}
//泛型方法
public <T> void print(T t) {
System.out.println(t);
}泛型只在编译期存在,编译后所有泛型参数被擦除为限定类型或 Object,以及生成必要的类型检查和强制类型转换。
比如List<String> list = new ArrayList<>();,在编译后变为List list = new ArrayList(); 这个过程称为类型擦除,由于这个机制,我们不能创建一个泛型数组,程序在运行时也无法获取泛型类型信息。
10. 反射
Java的反射机制是指在运行时动态获取类的信息,并操作类的属性、方法、构造器的能力。
优点在于动态性强,非常适用于框架的设计,可以访问私有成员,方便解耦。缺点是性能较低且破坏封装性,影响代码可读性。
应用举例:
//扫描类方法
Class<?> clazz = Person.class;
for (Method m : clazz.getDeclaredMethods()) {
System.out.println("方法名:" + m.getName());
}11. 代理
代理模式是一种设计模式,通过引入一个代理对象来控制对目标对象的访问。
在Java中,代理分为两类:
静态代理:程序员手动编写代理类
动态代理:在运行时动态创建代理类(JDK Proxy、CGLIB)
静态代理:
目标类和代理类需要实现同一个接口,每个接口都需要一个代理类,拓展性差维护成本高。
示例:
//接口
interface Service {
void doSomething();
}//代理类
class ServiceProxy implements Service {
private Service target;
public ServiceProxy(Service target) {
this.target = target;
}
@Override
public void doSomething() {
System.out.println("Before...");
target.doSomething();
System.out.println("After...");
}
}//目标类
class ServiceImpl implements Service {
public void doSomething() {
System.out.println("Doing something...");
}
}动态代理
Spring 默认使用 JDK 代理,如果类未实现接口则切换到 CGLIB
JDK动态代理:
JDK 提供的动态代理通过反射 + Proxy.newProxyInstance 在运行时生成代理类。前提是目标类必须实现接口。
核心接口为InvocationHandler,示例:
class MyInvocationHandler implements InvocationHandler {
private Object target;
public MyInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println("前置增强");
Object result = method.invoke(target, args);
System.out.println("后置增强");
return result;
}
}创建代理对象:
Service target = new ServiceImpl();
Service proxy = (Service) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
new MyInvocationHandler(target)
);
proxy.doSomething();工作流程为:JVM 生成一个代理类 Proxy,实现目标对象的所有接口;所有方法调用都转发到 InvocationHandler.invoke();在 invoke 中执行增强逻辑,再调用目标对象方法。
CGLIB动态代理
当目标类没有实现接口时,JDK 动态代理无法生效,此时可以使用 CGLIB。
CGLIB 通过 ASM 技术再运行时动态生成一个目标类的子类,覆盖父类方法实现增强。
例如:
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(Target.class);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
System.out.println("Before...");
Object result = proxy.invokeSuper(obj, args);
System.out.println("After...");
return result;
}
});
Target proxy = (Target) enhancer.create();12. 注解
注解是Java5引入的一直元数据机制,用于给类、字段、方法添加补充信息,供编译器、工具、框架在编译或运行时使用。
本质就是继承于Annotation的一个特殊接口:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
//本质为继承Annotation
public interface Override extends Annotation{
}注解按功能可以分为三类:
源代码注解:编译后丢弃,如@Override
编译期注解:编译到class文件,但运行期不存在
运行期注解:在运行时可以通过反射读取,框架中经常使用
Java还提供了一些元注解,可以自定义注解,比如@Target表示注解的位置,@Retention表示注解生效的位置,@Documented表示是否加入Javadoc,@Inherited 表示子类是否继承父类注解。
例如:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Log {
String value() default "default log";
}注解只有被解析后才会生效,常见的解析方法有两种:
编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用@Override 注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。
运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的 @Value、@Component)都是通过反射来进行处理的。
//反射读取注解
Method method = clazz.getDeclaredMethod("test");
if (method.isAnnotationPresent(Log.class)) {
Log log = method.getAnnotation(Log.class);
System.out.println(log.value());
}13. SPI
SPI是Java提供的一种服务发现机制,允许接口的实现者将实现声明到配置文件中,使用者在运行时动态加载实现类而无需在编译期依赖具体实现。
Java 提供 java.util.ServiceLoader 来加载服务:
ServiceLoader<MyService> loader = ServiceLoader.load(MyService.class);ServiceLoader会扫描META-INF/services/<接口全限定名>,读取文件里的每一行实现类名称,使用 懒加载(Lazy Initialization) 实例化实现类,返回可迭代对象,可遍历所有实现类。
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
14. 序列化与反序列化
序列化:将数据结构或对象转换成可以存储或传输的形式,通常是二进制字节流,也可以是 JSON, XML 等文本格式
反序列化:将在序列化过程中所生成的数据转换为原始数据结构或者对象的过程
序列化和反序列化常见应用场景:
对象在进行网络传输(比如远程方法调用 RPC 的时候)之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化;
将对象存储到文件之前需要进行序列化,将对象从文件中读取出来需要进行反序列化;
将对象存储到数据库(如 Redis)之前需要用到序列化,将对象从缓存数据库中读取出来需要反序列化;
将对象存储到内存之前需要进行序列化,从内存中读取出来之后需要进行反序列化。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
Java中的类要序列化必须实现Serializable接口:
import java.io.Serializable;
public class User implements Serializable {
private String name;
private int age;
}每个可序列化类最好定义一个serialVersionUID用来校验 类的版本是否一致,不手动写时 JVM 会自动生成,但自动生成的值不稳定且可能导致生产环境不可反序列化旧对象:
private static final long serialVersionUID = 1L;transient 修饰的字段不会被序列化。
Java原生序列化有严重的安全风险,性能差,一般不使用。